2022-STID-Quant Trading
Le projet consiste à créer un modèle d'apprentissage automatique qui pourrait prédire le prix de clôture de la devise du lendemain sur la base des données OHLC des jours précédents, indicateurs ( Bande de Bollinger )
www.quant-alcotous.ga
Slides & Videos
Members
| Name | Contribution |
|---|---|
| Rayane BOUGUERA | - Rédaction du cahier des charges - État de l'art ( Business Aspect / Technical Aspect ) - Extraction des données de Yahoo finance - Nettoyage et organisation des données - Analyse : - Estimation du Bêta ( ponctuelle et par intervalle de confiance ) - Calcule de l’indicateur ( Bande de Bollinger ) - Split train and test data - Initialisation du modèle Random forest - Création des visualisations - Simulation de la stratégie ( Backtest) - Powerpoint et vidéo - Soutenance |
State of the Art
Business Aspect
Quantitative Trading Definition - Investopedia
Qu’est-ce que le trading quantitatif ?
Le trading quantitatif est un type de stratégie de marché qui s’appuie sur des modèles mathématiques et statistiques pour identifier – et souvent exécuter – des opportunités. Les modèles sont pilotés par une analyse quantitative, d’où la stratégie tire son nom. Il est souvent appelé « trading quantitatif », ou parfois simplement « quant ». L’analyse quantitative utilise la recherche et la mesure pour décomposer des modèles complexes de comportement en valeurs numériques. Il ignore l’analyse qualitative, qui évalue les opportunités en fonction de facteurs subjectifs tels que l’expertise en gestion ou la force de la marque. Le trading quantitatif nécessite souvent beaucoup de puissance de calcul, il a donc traditionnellement été utilisé exclusivement par les grands investisseurs institutionnels et les fonds spéculatifs. Cependant, ces dernières années, les nouvelles technologies ont permis à un nombre croissant de Trader individuels de s’impliquer également.
Qui utilise le trading quantitatif ?
Le trading quantitatif est principalement utilisé par les institutions financières et les fonds spéculatifs, bien que les individus soient également connus pour s’engager dans une telle stratégie. Une fois la stratégie de trading construite, les transactions peuvent être exécutées manuellement ou automatiquement à l’aide de ces stratégies. L’idée clé est de choisir des investissements ou de construire une stratégie de trading basée uniquement sur l’analyse mathématique. Renaissance Technologies : est un fonds alternatif d’origine américaine créé en 1982 par James Simons. Les actifs financiers actuellement gérés s’élèvent à plus de 15 milliards de dollars US. Renaissance Technologies emploie plus de 300 personnes. Two Sigma : Investments est un hedge fund basé à New York qui a recours à un ensemble de technologies, parmi lesquelles l’intelligence artificielle, l’apprentissage automatique et le calcul distribué, pour ses stratégies de trading. Le fonds est dirigé par John Overdeck et David Siegel, il gère 35 milliards de dollars.
Trading quantitatif vs algorithmique
Les traders algorithmiques (algo) utilisent des systèmes automatisés qui analysent les modèles de graphique, puis ouvrent et clôturent des positions en leur nom. Les traders quantitatifs utilisent des méthodes statistiques pour identifier, mais pas nécessairement exécuter, les opportunités. Bien qu’elles se chevauchent, ce sont deux techniques distinctes qu’il ne faut pas confondre. Voici quelques distinctions importantes entre les deux :
- Les systèmes algorithmiques s’exécuteront toujours en votre nom. Certains traders quantitatifs utilisent des modèles pour identifier les opportunités, mais ouvrent ensuite la position manuellement
- Le trading quantitatif utilise des méthodes mathématiques avancées. L’algorithmique a tendance à s’appuyer sur une analyse technique plus traditionnelle
- Le trading algorithmique utilise uniquement l’analyse graphique et les données des bourses pour trouver de nouvelles positions. Les traders quantiques utilisent de nombreux ensembles de données différents
Quelles données un quant trader pourrait-il consulter ?
Les deux points de données les plus couramment examinés par les commerçants quantitatifs sont le prix et le volume. Mais tout paramètre qui peut être distillé en une valeur numérique peut être intégré dans une stratégie. Certains traders, par exemple, peuvent créer des outils pour surveiller le sentiment des investisseurs sur les réseaux sociaux. Il existe de nombreuses bases de données accessibles au public que les commerçants quantitatifs utilisent pour informer et construire leurs modèles statistiques. Ces ensembles de données alternatifs sont utilisés pour identifier des modèles en dehors des sources financières traditionnelles, telles que les fondamentaux.
Technical Aspect
How Quantitative Trading Works
Les traders quantitatifs développent des systèmes pour identifier de nouvelles opportunités – et souvent, pour les exécuter également. Bien que chaque système soit unique, ils contiennent généralement les mêmes composants :
Voici un aperçu de chacun d’eux :
Stratégie
Avant de créer un système, les quants rechercheront la stratégie qu’ils veulent qu’il suive. Souvent, cela prend la forme d’une hypothèse. Notre exemple ci-dessus utilise l’hypothèse que le FTSE a tendance à effectuer certains mouvements à des moments particuliers chaque jour, par exemple.
Avec une stratégie en place, la tâche suivante consiste à la transformer en un modèle mathématique, puis à l’affiner pour augmenter les rendements et réduire les risques.
C’est également le point auquel un quant décidera de la fréquence à laquelle le système négociera. Les systèmes à haute fréquence ouvrent et ferment de nombreuses positions chaque jour, tandis que les systèmes à basse fréquence visent à identifier les opportunités à plus long terme.
Backtesting
Le backtesting consiste à appliquer la stratégie à des données historiques, pour avoir une idée de la façon dont elle pourrait se comporter sur les marchés en direct. Les quants utiliseront souvent ce composant pour optimiser davantage leur système, en essayant de résoudre tous les problèmes.
Le backtesting est un élément essentiel de tout système de trading automatisé, mais le succès ici n’est pas une garantie de profit lorsque le modèle est en ligne. Il existe diverses raisons pour lesquelles une stratégie entièrement backtestée peut toujours échouer : notamment des données historiques inexactes ou des mouvements de marché imprévisibles.
Un problème courant avec le backtesting est d’identifier la volatilité qu’un système verra lorsqu’il générera des rendements. Si un trader ne regarde que le rendement annualisé d’une stratégie, il n’obtient pas une image complète.
Exécution
Chaque système contiendra un composant d’exécution, allant d’entièrement automatisé à entièrement manuel. Une stratégie automatisée utilise généralement une API pour ouvrir et fermer des positions aussi rapidement que possible sans aucune intervention humaine. Un manuel peut impliquer que le commerçant appelle son courtier pour effectuer des transactions.
Les systèmes HFT sont entièrement automatisés par nature – un trader humain ne peut pas ouvrir et fermer des positions assez rapidement pour réussir.
Un élément clé de l’exécution consiste à minimiser les coûts de transaction, qui peuvent inclure les commissions, les taxes, le glissement et le spread. Des algorithmes sophistiqués sont utilisés pour réduire le coût de chaque transaction – après tout, même un plan réussi peut être annulé si chaque position coûte trop cher à ouvrir et à fermer.
Project Description
Problem Definition
Challenges & Motivation
Real and Complete Usecases
Je pense que la régression ML peut donner des informations sur les configurations de stratégie de trading qui autrement resteraient cachées et en même temps, ce n’est pas tant une boîte noire que vous pouvez évaluer les prédicteurs et décider lesquels utiliser.
De plus, j’échange des paires de devises Forex et j’espère que je pourrais l’utiliser sur de vraies configurations commerciales. Appliquez l’apprentissage automatique pour prédire la tendance à l’aide de prédicateurs, d’indicateurs techniques et d’un indicateur de sentiment, afin de créer une stratégie plus robuste qui tiendrait compte à la fois des aspects techniques et fondamentaux.
Technical Description
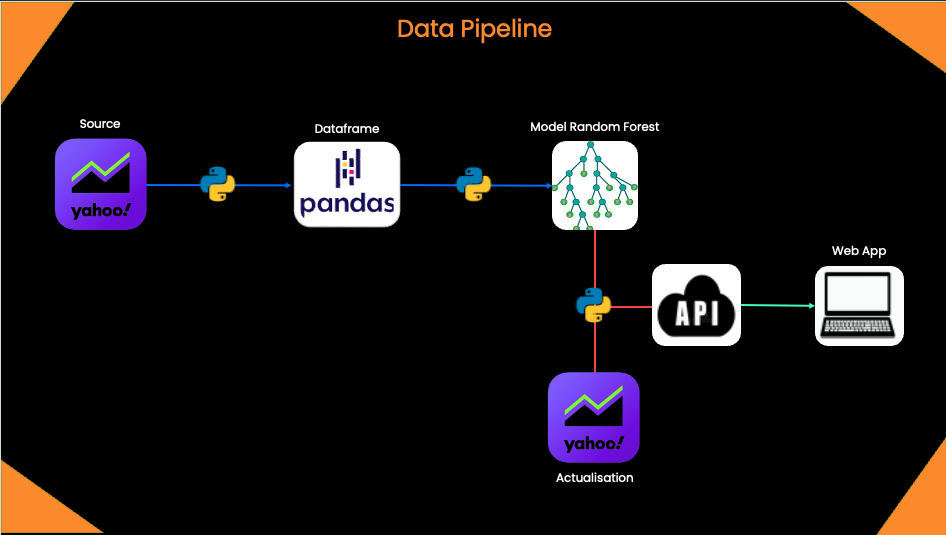
Les forêts aléatoires ( Random Forest ) sont basées sur des techniques d’apprentissage d’ensemble. Ensemble, signifie simplement un groupe ou une collection, qui dans ce cas, est une collection d’arbres de décision, ensemble appelés forêts aléatoires. La précision des modèles d’ensemble est meilleure que la précision des modèles individuels en raison du fait qu’il compile les résultats des modèles individuels et fournit un résultat final.
Comment sélectionner les caractéristiques de l’ensemble de données pour construire des arbres de décision pour la forêt aléatoire ?
Les fonctionnalités sont sélectionnées de manière aléatoire à l’aide d’une méthode connue sous le nom d’agrégation bootstrap ou d’ensachage. À partir de l’ensemble des fonctionnalités disponibles dans l’ensemble de données, un certain nombre de sous-ensembles d’apprentissage sont créés en choisissant des fonctionnalités aléatoires avec remplacement. Cela signifie qu’une caractéristique peut être répétée dans différents sous-ensembles de formation en même temps.
Par exemple, si un jeu de données contient 20 caractéristiques et que des sous-ensembles de 5 caractéristiques doivent être sélectionnés pour construire différents arbres de décision, ces 5 caractéristiques seront sélectionnées de manière aléatoire et toute entité peut faire partie de plusieurs sous-ensembles. Cela garantit le caractère aléatoire, ce qui réduit la corrélation entre les arbres, surmontant ainsi le problème de surajustement.
Une fois les caractéristiques sélectionnées, les arbres sont construits en fonction de la meilleure répartition. Chaque arbre donne une sortie qui est considérée comme un “vote” de cet arbre pour la sortie donnée. Le résultat
qui reçoit le maximum de ‘votes’ est choisi par la forêt aléatoire comme sortie/résultat final ou dans le cas de variables continues, la moyenne de toutes les sorties est considérée comme la sortie finale.
Hardware
Materials
| Image | Name | Part Number | Price | Count | Link |
|---|---|---|---|---|---|
| Python | 100 % | 0 | 1 | 🛒 |
Schematic