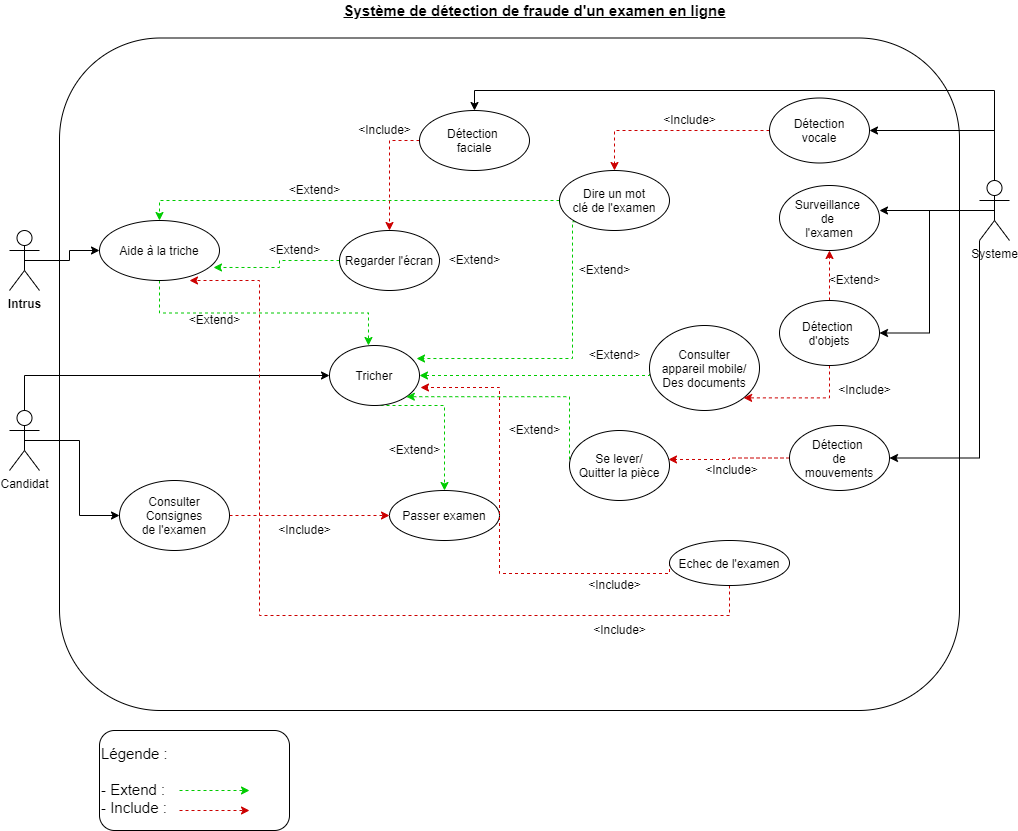
2022-G5-Exa-M_Alexis-Ismael
Réalisation d'un système d'intelligence artificielle permettant de détecter une fraude avérée durant un examen en ligne.
Slides & Videos
Members
| Name | Contribution |
|---|---|
| Alexis CHANDARA | Nous avons tout fait ensemble étant donné que le PC d'Alexis a des soucis techniques. 19/01 -> Connexion sans fil entre le téléphone et l'ordinateur. 20/01 -> Implémentation de l'accéléromètre. 23/01 -> Installation d'openCV pour l'utilisation de la caméra et la détection d'objets. 26/01 -> Bug accéléromètre, on a décidé de tout recommencer. 27/01 -> Implémentation d'un nouvel accéléromètre 03/02 -> Rectification des problèmes causés par l'accéléromètre. 04/02 -> Implémentation du Serveur. 10/02 -> Envoi des données de l'accéléromètre du client vers le serveur par socket. 11/02 -> Implémentation d'un code qui permet de détecter des objets via la caméra du téléphone. 13/02 -> Enregistrement du nom des objets dans un fichier logLabel.txt. 14/02 -> Récupération du nom des objets par le serveur à partir du fichier logLabel.txt 16/02 -> Implémentation de la reconnaissance faciale côté serveur. 17/02 -> Implémentation de la reconnaissance vocale côté serveur. 19/02 -> Retranscription vocal en texte sur un fichier script.txt. 21/02 -> Parallélisation des algorithmes implémentés dans une classe Main. 22/02 -> Mis en place des scénarios définis pour les fraudes avérés, mis en place des pop-ups avertissant le candidat. 23/02 -> Rédaction du rapport, transfert du code sur github. |
| Ismael DKHISSI | Nous avons tout fait ensemble étant donné que le PC d'Alexis a des soucis techniques. 19/01 -> Connexion sans fil entre le téléphone et l'ordinateur. 20/01 -> Implémentation de l'accéléromètre. 23/01 -> Installation d'openCV pour l'utilisation de la caméra et la détection d'objets. 26/01 -> Bug accéléromètre, on a décidé de tout recommencer. 27/01 -> Implémentation d'un nouvel accéléromètre 03/02 -> Rectification des problèmes causés par l'accéléromètre. 04/02 -> Implémentation du Serveur. 10/02 -> Envoi des données de l'accéléromètre du client vers le serveur par socket. 11/02 -> Implémentation d'un code qui permet de détecter des objets via la caméra du téléphone. 13/02 -> Enregistrement du nom des objets dans un fichier logLabel.txt. 14/02 -> Récupération du nom des objets par le serveur à partir du fichier logLabel.txt 16/02 -> Implémentation de la reconnaissance faciale côté serveur. 17/02 -> Implémentation de la reconnaissance vocale côté serveur. 19/02 -> Retranscription vocal en texte sur un fichier script.txt. 21/02 -> Parallélisation des algorithmes implémentés dans une classe Main. 22/02 -> Mis en place des scénarios définis pour les fraudes avérés, mis en place des pop-ups avertissant le candidat. 23/02 -> Rédaction du rapport, transfert du code sur github. |
State of the Art
Business Aspect
Introduction
De nos jours avec la pandémie mondiale qui sévie, énormément de personnes et d’entreprises ont été contraint de passé totalement au numérique pour pouvoir travailler ou bien continuer à faire fonctionner l’économie mondiale.
Plusieurs problèmes se pose donc avec l’arrivée massif du distanciel comme le fait d’assurer l’intégrité d’un examen passé en ligne afin d’éviter toute fraude.
Pearson VUE
Plusieurs technologies déjà présentes sur le marché essaient de répondre à cette problématique comme par exemple la solution Pearson Vue afin de pouvoir faire passer des certifications en ligne tout en respectant les conditions de cette dernière.
![]()
Le logiciel de surveillance en ligne VUE fournit un système d’enregistrement unique pour plusieurs plates-formes de livraison de tests dans le monde. Les utilisateurs peuvent programmer n’importe quel examen à la maison à partir de la liste d’examens disponible lors de l’inscription.
Vous devez simplement vous connecter et sélectionner l’examen acheté dans les 15 minutes suivant l’heure de rendez-vous prévue pour commencer l’examen.
Les caractéristiques de Pearson VUE :
Prémuni de son tableau de bord unique avec visualisation facile des données, elle facilite la compréhension du déroulement de l’examen.
Grâce à son système de correspondance faciale et de vérification d’identité, la sécurité est assurée avant le commencement de l’examen. En effet il vous sera demandé de vous prendre en photo de face puis de prendre des photos recto/verso d’une pièce d’identité afin que l’intelligence artificiel puisse vous reconnaitre grâce à une reconnaissance facial.
Une surveillance en direct alimentée par l’IA permet à l’application de pouvoir surveiller les candidats durant l’examen. Cette technologie est couplée avec la surveillance humaine en début d’examen afin de vérifier si toutes les consignes ont été respecté.
Avantages :
Cette solution apporte beaucoup d’avantages comme :
– Planification/reprogrammation flexible des examens
– Conformité aux lois mondiales sur la confidentialité des données
Inconvénients :
Cependant certains freins peuvent poser un problème comme :
– Nécessite une forte connectivité Internet (3 Mbps +)
– Capacité de surveillance : sur une base de demande individuelle
Cette solution s’adresse aux preneurs et directeurs d’examens de certification et de licence tels que ICTPI, ITB, évaluations militaires américaines, etc.
Au niveau de la tarification le prix varie en fonction de vos exigences de test. Donc plus la surveillance sera renforcée plus le prix augmentera.
Autres exemples du marché
D’autres solutions similaires existent sur le marché comme :
– Wheebox
![]()
– ExamShield

Reconnaissance faciale – OPENCV
A l’heure actuel, certaines solutions ne proposent pas leur code source gratuitement en ligne, cependant énormément de personnes ont pu concevoir des algorithmes répondant à des sous problèmes.
Par exemple comme la détection d’objets utilisant un module appelé OpenCv qui est disponible gratuitement sur internet.
Ce module permet de faire énormément de choses, comme détecter en direct le visage d’une personne ou bien les yeux et même des objets du quotidien.
Voici une vidéo YouTube d’une personne qui montre l’implémentation d’une reconnaissance facial avec ce module :
OpenCV Python Tutorial #8 – Face and Eye Detection – YouTube
D’autre youtubeur propose ce genre de contenue qui permet d’implémenter plus facilement ce genre de solution.
Reconnaissance vocale
On peut aussi se pencher sur la problématique de la voix lors d’un examen. Il ne faudrait pas qu’une personne puisse communiquer avec une autre durant son test.
Ici divers vidéo et implémentation sont trouvable sur GitHub ou bien sur YouTube comme cette vidéo qu’on a trouvé :
Speech Recognition in Python – YouTube
Ce Youtubeur propose divers solution d’intelligence artifice sur sa page GitHub que l’on peut utiliser gratuitement :
NeuralNine (NeuralNine) (github.com)
Détection de mouvements
• Les accéléromètres sont utilisées pour enregistrer à la fois les accélérations statiques (la gravité) et dynamique (choc, mouvement).
• Une des applications principale des accéléromètre est le calcul d’inclinaison. Grace à l’effet de la gravité, un accéléromètre peut vous dire comment est orienté votre objet par rapport à la terre. Sur un smartphone, ça vous permet de passer du mode portrait au mode paysage.
• Un accéléromètre peut aussi capter les mouvement. Par exemple, dans les WiiMote de Nintendo, il sont utilisés pour reproduire à l’écran vous mouvement au tennis ou au golf.

• Enfin, un accéléromètre peut aussi être utilisé pour capter si un objet est en chute libre. C’est utilisé pour protéger des objets fragile (disque dur), car une chute libre implique in fine un choc !
MICRO ELECTRO MECHANICAL SYSTEM (MEMS)
-Premier accéléromètre en 1980-90 : Airbag
-En 2006, convergence de points positifs- MEMS low cost: après 15 ans de recherche active, il devient possible de faire des capteurs de mouvement pour moins d’1$ – Le marché de consommateur d’éléctronique explose avec des produit innovants pour le jeu, les smartsphones, etc ..
– Dans un marché qui explose, les acteurs cherchent à se différencier en cherchant des nouvelle interfaces
IHM et à cause des faibles tailles des objets.
Détection d’objets
On peut retrouver dans cet article le fonctionnement de la détection d’objet qui est détaillé avec des algorithmes de machine Learning tel que le Deep learning avec ces Réseaux de neurones profond :
Qu’est-ce que la détection d’objet ? – Saagie
Deep Learning
Pour aller plus loin les recherches du Co-fondateur du Deep Learning Yan LeCun nous explique ce que c’est que le Deep Learning :
L’apprentissage profond permet aux modèles informatiques composés de plusieurs couches de traitement d’apprendre des représentations de données avec plusieurs niveaux d’abstraction.
Ces méthodes ont considérablement amélioré l’état de l’art en matière de reconnaissance vocale, de reconnaissance visuelle d’objets, de détection d’objets et de nombreux autres domaines tels que la découverte de médicaments et la génomique.
L’apprentissage en profondeur découvre une structure complexe dans de grands ensembles de données en utilisant l’algorithme de rétropropagation pour indiquer comment une machine doit modifier ses paramètres internes qui sont utilisés pour calculer la représentation dans chaque couche à partir de la représentation dans la couche précédente.
Les réseaux convolutifs profonds ont permis des percées dans le traitement des images, de la vidéo, de la parole et de l’audio, tandis que les réseaux récurrents ont mis en lumière des données séquentielles telles que le texte et la parole.
Examus
Un autre exemple de solution complète d’un système permettant la surveillance d’examen en ligne est Examus :

Examus a développé une solution avancée de surveillance par intelligence artificielle qui empêche les tentatives de fraude lors des examens en ligne et surveille le comportement des étudiants pendant l’examen.
Examus permet aux universités d’obtenir des résultats d’examens en ligne validés et fiables. Cela permet aux étudiants d’étudier et de passer des examens à distance depuis n’importe quel endroit du monde. L’objectif principal d’Examus est d’améliorer le processus de formation et de le rendre facile et accessible à tous ceux qui veulent étudier à distance et obtenir les résultats des examens.
La solution de surveillance brevetée d’Examus, basée sur la vision par ordinateur et l’intelligence artificielle, est déjà intégrée aux principales plateformes de test et aux systèmes de gestion de l’apprentissage tels que Moodle, OpenedX. La solution de surveillance d’Examus IA peut être intégrée dans n’importe quel système de gestion de l’éducation (LMS) ou plate-forme de test.
Conclusion
Nous avons donc vu une panoplie de nouvelle technologie révolutionnaires permettant de répondre à la problématique posé plus haut.
Enormément de personnes se sont penché sur les sous problème de notre problématique de base, il est donc facile de trouver des ressources afin de pouvoir développer une solution qui répond au mieux à la problématique.
Des grand chercheurs comme Yan LeCun un des pionnier du Deep Learning ont fait avancer la technologie afin de pouvoir mieux aider les futur projets qui dessineront le monde de demain.
En conclusion de nos jours les technologies ont bien avancé et nous permet de mieux comprendre les besoins présents et futur, grâce à la recherche mais aussi grâce à des plateformes permettant la mise en ligne de code source utilisable gratuitement comme nous avons pu le voir.
Technical Aspect
Pour la connexion sans fil entre le téléphone et l’ordinateur :
Veuillez connecté votre téléphone à l’ordinateur avec un câble usb.
Vérifier que votre téléphone et votre ordinateur sont connecté sur le même réseau (même WIFI).
Prenez soin d’autoriser à chaque fois qu’une demande d’autorisation s’affiche sur votre téléphone.
Ensuite, effectuer les commandes suivantes sur le terminal d’Android Studio :
Il faut aller sur votre Sdk/Platform-tools :
cd C:\Users\User\AppData\Local\Android\Sdk\platform-tools
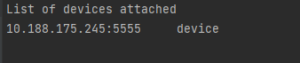
adb devices -> pour regarder les appareils connectés sur le port de l’ordinateur.
adb tcpip 5555 -> redémarrer via le mode TCP sur le port 5555
adb connect <IP> -> pour connecter le téléphone à l’ordinateur. (Remplir le champ <IP> par l’IP de votre téléphone.
adb devices -> pour vérifier si votre appareil s’est connecté
Ensuite il faut débrancher le câble qui relie votre téléphone à l’ordinateur !
Puis, effectuer les commandes suivantes :
adb kill-server
adb connect <IP>
adb devices
Votre téléphone est bel et bien connecté par WIFI sur votre ordinateur.
Détection de mouvement :
On va utiliser un accéléromètre pour détecter le mouvement du téléphone.
Sur Android Studio, il nous est possible d’accéder aux capteurs sensorielles du téléphone, en utilisant JAVA, notre classe doit implémenter SensorEventListener permettant cela :
![]()

Il nous faut détecter l’accélération sur l’axe X,Y et Z, on a donc suivi ce tuto : https://www.youtube.com/watch?v=pkT7DU1Yo9Q&t=499s
Conceptuellement, un capteur d’accélération détermine l’accélération qui est appliquée à un dispositif (Ad) en mesurant les forces qui sont appliquées au capteur lui-même (Fs) en utilisant la relation suivante :

Cependant, la force de gravité influence toujours l’accélération mesurée selon la relation suivante :

Pour cette raison, lorsque l’appareil est posé sur une table (et n’accélère pas), l’accéléromètre lit une magnitude de g = 9,81 m/s2. De même, lorsque l’appareil est en chute libre et accélère donc rapidement vers le sol à 9,81 m/s2, son accéléromètre lit une magnitude de g = 0 m/s2.
Par conséquent, pour mesurer l’accélération réelle de l’appareil, la contribution de la force de gravité doit être retirée des données de l’accéléromètre. Ceci peut être réalisé en calculant l’amplitude de l’accélération qui est la racine carrée de la somme des carrés de chaque composant auquel on retire la force de pesanteur:
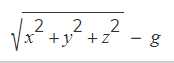
Envoi des données de l’accéléromètre au serveur :
Pour envoyer nos données de l’accéléromètre au serveur, on établit une connexion socket entre notre code JAVA sur Android Studio et notre code Python sur spyder.
Sur android Studio notre classe send s’occupe de l’envoi sur le port 8000 :
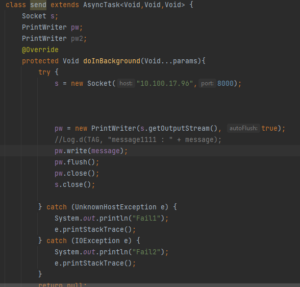
Serveur :
Et sur Spyder, on a fait une classe Serveur permettant de se connecter par socket au même port, et on récupère le message envoyé par le client :

Détection d’objet:
Notre application va détecter en temps réel les objets qui entourent le candidat à partir de la caméra du téléphone.
Il faut tout d’abord installer OpenCV pour Android Studio, on a suivi ce tuto Youtube :
On a suivi les étapes d’installation comme NDK par exemple et la personnalisation du Gradle ici :
Ensuite pour le code on a repris celui qui est dans ce github :
https://github.com/spmallick/learnopencv/tree/master/DNN-OpenCV-Classification-Android/img_classification_android/app/src/main
MobileNets
Tout d’abord, il faut savoir ce que c’est que les MobileNets, ce sont une famille de modèles DNN à faible latence et à faible consommation d’énergie. nous utilisons le modèle MobileNetV2 pour transformer l’application Java finale.
DNN est un système de gestion de contenu. Il s’agit d’une application Web dynamique, dotée d’une base de données permettant de gérer directement en ligne son contenu et sa configuration.
L’architecture MobileNetV2 a été introduit en 2019 : MobileNetV2: Inverted Residuals and Linear Bottlenecks
L’idée du réseau est son adéquation aux appareils mobiles et aux plates-formes aux ressources limitées. Cela a été réalisé avec la réduction des opérations et de la consommation de mémoire sans impact sur la précision du modèle grâce au nouveau module de couche appelé « résidu inversé avec goulot d’étranglement linéaire ».
Les données d’entrée du réseau sont filtrées avec des convolutions légères en profondeur, on utilise donc un réseau de neurones convolutif. D’autres convolutions linéaires transformeront les caractéristiques obtenues en une représentation de faible dimension.
C’est pour cela qu’on utilise un fichier au format onnx : pytorch_mobilenet.onnx dans notre dossier assets, pour qu’il puisse être importé et utilisé dans notre application.
Open Neural Network Exchange (ONNX) est un projet d’IA open source. Son objectif est de rendre possible l’échange entre les modèles de réseaux de neurones et d’autres cadres.
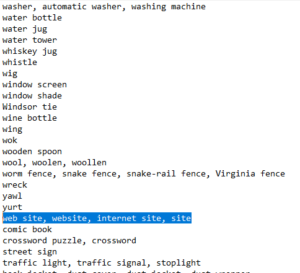
Pour un décodage plus poussé des prédictions, on utilise un fichier texte contenant tous les noms des objets que notre application peut détecter, dans notre fichier imagenet_classes.txt qui se trouve dans le dossier assets :
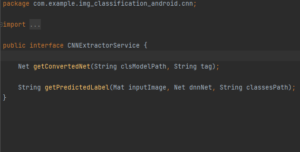
le fichier CNNExtractorServiceImpl qui implémente CNNExtractorService permet de retourner les labels d’image.
Contenu de CNNExtractorService :
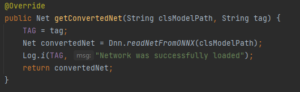
La méthode getConvertedNet utilise OpenCV org.opencv.dnn.Net obtenu à partir du fichier pytorch_mobilenet.onnx:
getPredictedLabel fournit une inférence et transforme les prédictions MobileNet en classe d’objet résultante :
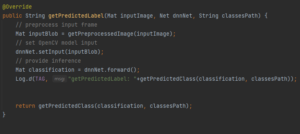
Ici le blob est notre image d’entrée normalisé, re-dimensionné avec la méthode getPreprocessedImage qui est définit comme ce qui suit :
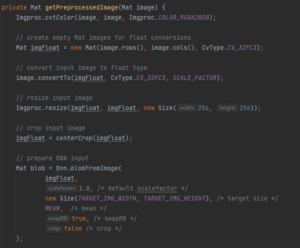
On met ce blob en paramètre avec org.opencv.dnn.Net :
![]()
Et on obtient l’inférence de notre classe avec la dernière ligne.
![]()
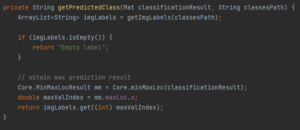
La méthode getPredictedClass permet d’inférer, de prédire la classe :
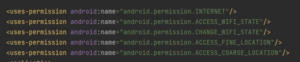
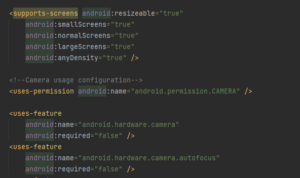
Notre fichier AndroidManifest.xml permet certaines fonctionnalités comme configurer l’accès à internet, à la caméra et à configurer l’orientation de l’écran du téléphone :
MainActivity.java :
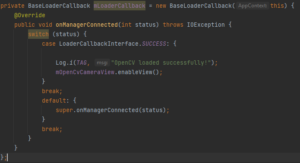
On a d’abord l’initialisation du Manager :
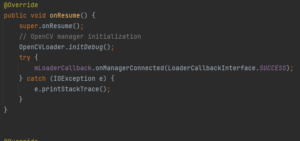
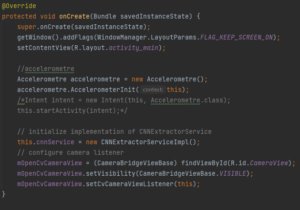
Puis dans oncreate, on va utiliser notre CNNExtractorService, l’accéléromètre, ainsi que la configuration de la caméra :
Lorsque la caméra démarre, il faut utiliser la méthode onCameraViewStarted , cette méthode permet d’initialiser le model MobileNet, pour lire son .onnx qui se trouve dans org.opencv.dnn.Net:
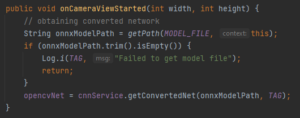
Puis la méthode onCameraFrame, Ici la logique est exécutée au moment de la livraison de la trame ; l’objet renvoyé est de type Mat et sera affiché dans l’application. Dans cette méthode, nous traitons les trames d’entrée en les transmettant à MobileNet et en obtenant les classes prédites.
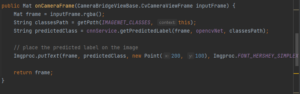
onCameraViewStopped() – la logique est invoquée lors de l’interruption de l’aperçu de la caméra. Une fois la méthode invoquée, onCameraFrame() arrête les provisions des cadres. Nous n’implémentons aucune logique spécifique dans cette méthode, la laissant vide :

Envoi des labels au serveur :
Pour envoyer les labels (noms) d’objets au serveur, on va écrire en temps réel dans le logcat le nom des objets que notre appareil détecte :
![]()
Ensuite, on va constamment enregistrer le logcat dans un fichier logLabel.txt en tapant cette commande sur le terminal d’Android Studio.
Il faut taper cette commande avant d’exécuter le code d’Android Studio !
La commande est la suivante :
adb logcat -v long time > C:\Users\User\AndroidStudioProjects\logLabel.txt
Grâce à cette commande, à chaque fois que notre appareil détecte un objet, le nom de cette objet sera écrit dans le fichier logLabel.txt.
Ensuite, notre serveur va se charger de lire constamment (avec une boucle while) le fichier logLabel.txt, et récupérer le nom de ces objets lorsqu’il en croise un :
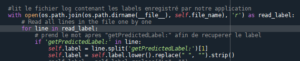
Reconnaissance faciale :
Il s’agit de notre fichier Cam.py qui est une classe python.
On installe OpenCV API pour python : conda install opencv
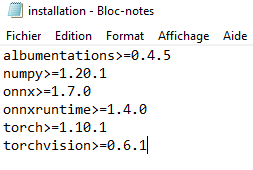
Effectuer la commande pip install -r installation.txt pour installer les package requis :
On a suivi cette vidéo : https://youtu.be/mPCZLOVTEc4
On a garder uniquement la détection du visage, car on a trouvé que la détection des yeux n’étaient pas pertinent pour ce qu’on voulait.
Reconnaissance vocale :
Cette partie est implémenté dans notre fichier Voice_recognition.py qui est une classe python.
On a suivi cette vidéo pour retranscrire la détection vocale en texte : https://www.youtube.com/watch?v=9GJ6XeB-vMg&t=106s
On a du installer pyaudio sur windows : https://www.journaldunet.fr/web-tech/developpement/1498829-comment-installer-pyaudio-sur-windows-et-eviter-l-erreur-error-microsoft-visual-c-14-0-is-required/
On a décidé de sauvegarder la retranscription vocale en texte sur un fichier script.txt dans le dossier voix_retranscription :
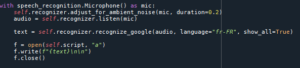
Main.py
Notre fichier main.py permet de paralléliser la reconnaissance vocale, la reconnaissance faciale, la détection de mouvement et l’écoute du client par le serveur via des Threads :
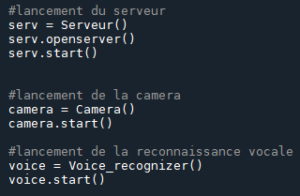
On ajoute un Thread condition d’arrêt pour permettre d’arrêter tous les threads lorsqu’on rencontre un scénario éliminatoire :

La fonction stop_code :
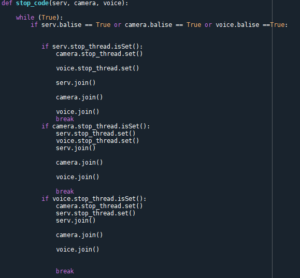
Les différentes balises utilisées valent True lorsqu’on rentre dans l’un des scénarios éliminatoires. Et dans ce cas on arrête tous les threads grâce à cette fonction ci-dessus.
Scénarios éliminatoires :
Pour les règles à respecter durant l’examen, on s’est inspiré du logiciel Microsoft OnVue permettant de détecter les fraudes :
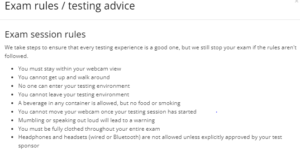
En effet, moi et Alexis avions eu l’occasion de pouvoir passer des certification Azure sur ce logiciel, et ces règles nous étaient présentées.
On a donc généré une pop-up permettant d’avertir le candidat des règles de l’examen avant qu’il le débute dans notre fichier main.py :
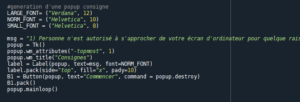
Il faut installer tkinter :
pip install tk
https://www.tutorialspoint.com/how-to-install-tkinter-in-python
Voici l’aperçu de la pop-up :
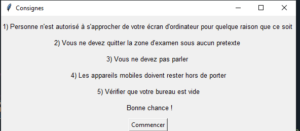
De la même manière on a généré des pop-ups avertissant le candidat de son élimination dans chaque scénario.
Cam.py :
Lorsqu’on détecte un deuxième visage se rapprochant de l’écran du candidat, cela est considéré comme de la triche, une pop-up apparait avertissant le candidat de son élimination :
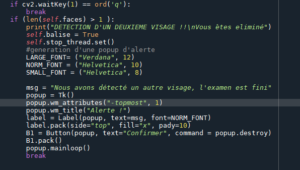
SocketServer.py :
Lorsqu’on détecte un mouvement brusque qui sort de l’ordinaire, comme par exemple quand le candidat se lève et sort de la pièce, cela est considéré comme de la triche, une pop-up apparait avertissant le candidat de son élimination :
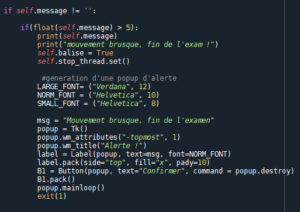
Lorsque notre application détecte un objet suspect que le candidat n’a pas le droit d’avoir proche de lui, cela est considéré comme de la triche, une pop-up apparait avertissant le candidat de son élimination :
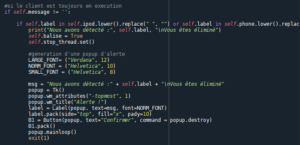
Parmi les objets éliminatoires, on retrouve :
-Les appareils mobiles
-Les feuilles, documents, fichiers, papiers
Voice_recognition.py
Tout ce que dit le candidat est enregistré en temps réel dans notre fichier script.py dans le dossier voix_retranscription.
Lorsqu’on détecte un mot clé faisant partie de l’examen, autrement dit, lorsqu’on lit un mot clé dans le fichier script.py (la lecture est en temps réelle).
Cela est considéré comme de la triche, une pop-up apparait avertissant le candidat de son élimination :
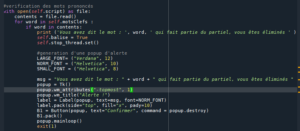
Parmi les mots clé, on a comme exemple :
-banane
-pomme
-poire
Project Description
Problem Definition
Challenges & Motivation
-Détection du visage
-Détection vocal
-Détection du mouvement
-Détection des objets
-Architecture Serveur/Client
-Connexion sans fil
Motivations :
Tous ces challenges nous permettent de surmonter certaines prérogatives qu'on peut rencontrer durant un examen en ligne.
Real and Complete Usecases
- Le candidat s’installe devant un bureau préalablement vide.
- Il met le téléphone sur son front.
- Il lit les consignes indiquées par le système.
- Il démarre l’examen en cliquant sur le bouton “commencer”.
- Si une fraude est avérée, il sera immédiatement avertit de son élimination.
Technical Description
- Connexion Serveur (Spyder) / Client (Android Studio) par socket : connexion sans fil ou avec fil.
- Implémentation d’un code JAVA permettant la détection d’objets via la caméra du téléphone sur Android Studio.
- Implémentation d’un algorithme permettant de récupérer la position du téléphone via ses capteurs sensoriels, et de calculer la vitesse du candidat sur Android Studio.
- Implémentation d’algorithmes d’intelligence artificiel permettant :
- La reconnaissance vocale. (Serveur)
- La reconnaissance faciale. (Serveur)
- La détection d’objets. (Client)
- Envoi de données Client -> Serveur.
- Synchronisation des algorithmes lors du lancement du système. (Threads)
- L’établissement des scénarios permettant de détecter une fraude.
- Avertissement du candidat via des pop-ups en cas d’évènements suspicieux.
- Arrêt complet du système en cas de fraude avérée.
- Historisation des évènements durant l’examen.