
2021-M2-Rakotomamonjy-4
On va établir un système de télésurveillance de l’examen à distance en utilisant une caméra de l'ordinateur et une caméra du portable, pour détecter la tricherie et faciliter la démarche de l’examen pendant la crise sanitaire.
Slides & Videos
Members
| Name | Contribution |
|---|---|
| PLS | Etudiant 1 : RAKOTOMAMONJY Andriatsiiavonana Sitraka Mbolatiana Email : mbolasitrakaa@gmail.com Github : https://github.com/Mbolasitrak 1. Programmer des fonctions pour évaluer la position de visage.l'inspiration est basé par ce lien https://www.youtube.com/watch?v=ibuEFfpVWlU .Et on a utilisé une méthode de division de grandeur et trigonométrie de base pour connaître l'inclinaison et direction de position de visage 2. Calculer et Afficher la durée de temps écoulé à chaque position de la tête. 3. Écrire l'état de l'art la partie technique 4. Proposer application Ip Webcam pour aider à connecter la caméra du portable sur l'ordinateur 5. Rédiger ett présenter le parti de présentation de l'évaluation de l'orientation de la tête 6. Résoudre le problème de l'envoye de fichier de grande taille qui est supérieure à 100 Mo vers notre repo de git Hub Etudiant 2: Zakia AMEZIANE Email : zakiaameziane5@gmail.com Github : https://github.com/zameziane62 1. Proposer des méthodes pour faire la détection des objets sur collab 2. Aider à faire les commentaires du code |
| EID | Etudiant 3 : QIAN Xiaotong Email : qianxiaotong96@gmail.com Github : https://github.com/qianxiaotong96 1. Apprendre des vidéos sur internet : https://www.youtube.com/watch?v=PmZ29Vta7Vc pour proposer une méthode de la reconnaissance faciale en utilisant opencv 2. Coopérer avec un membre du groupe pour faire l'affichage de la durée de chaque orientation de la tête 3. Faire référence au site :https://wizardforcel.gitbooks.io/hyry-studio-scipy/content/17.html , et écrire les fonctions records et read pour enregistrer et analyser la voix détectée pendant l'examen 4. Écrire l'état de l'art de la partie du business et les documents nécessaires à remplir. 5. Produire la vidéo de la démonstration et présentation 6. Gérer toutes les tâches de tous les membres du groupe Etudiant 4 : BIAN Yiping Email : bianyiping@gmail.com Github : https://github.com/YipingBIAN 1. Proposer la librairie face_recognition pour améliorer la reconnaissance faciale 2. Coopérer avec les autres pour finaliser la partie de la détection des objets 3. Rassembler les fonctions écrites par tous les membres du groupe 4. Utiliser multiprocessus pour augmenter la vitesse de l'exécution |
State of the Art
Business Aspect
Surveillance des examens en ligne par les universites
En raison du développement des techniques IA (surtout la reconnaissance faciale) et des règles sanitaires adoptées pour faire face à l’épidémie de COVID-19, on est obligé de remplacer les travails en présentiel par les travails à distance, en même temps, c’est compliqué de faire le changement entre ces deux modes, la télésurveillance des examens à distance est une représentation parmi toutes les difficultés rencontrées pendant l’épidémie. D’ailleurs, les établissements doivent se conformer au règlement général sur la protection des données (RGPD). Selon les informations sur internet, le marché mondial de la vidéosurveillance est en plein essor et devrait connaître une croissance annuelle moyenne de plus de 10% d’ici 2023. Cette technique est très demandé en France et dans le monde. Pour évider le tricher, il y a déjà des applications adaptées par les Universités européennes par exemple :
Evalbox - une plateforme d'évaluation pour gérer des tests QCM en ligne. Voici leur site officiel
– Anti triche avancé
Temps des questions limité. Mécanisme pour empêcher de sauter à une autre fenêtre durant le QCM. Pendant l’examen, suivi des étudiants en temps réel et affichage instantané des alertes de tricherie
– Tirage aléatoire
Créer un nouveau quiz de 50 questions peut prendre moins de 15 secondes grâce à la création automatique par tirage au sort dans vos banques de questions !
– Partage de QCM
Partage des QCM au niveau d’un groupe pédagogique, d’un établissement, d’une entreprise.
Centralisation de toutes les questions et constitution de banques de questions
Après avoir utilisé cette application, on a remarqué qu’il y a pas mal des gens redemandent de faire les examens en présentiel, à cause de plusieurs problèmes rencontrés pendant le test QCM en ligne, comme le temps limité ou le niveau de difficulté etc. Des fur et à mesure, il y a aussi des applications de surveillance de l’examen à distance par webcam comme suivant:
- En utilisant la webcam sur l’ordinateur de l’élève, la plateforme peut identifier le preneur d’examen et surveiller pendant l’examen pour tout comportement inhabituel
- Pour ce qui se passe derrière l’ordinateur en ajoutant une deuxième caméra, place derrière le preneur d’examen, toute la pièce est visible pendant l’examen, cela peut être n’importe quel appareil intelligent, comme un téléphone portable ou une tablette.
- Entièrement basé sur le Web sur n’importe quel système d’exploitation, rien n’est téléchargé sur l’ordinateur
Pourtant, même si après la crise sanitaire, cette technique va quand même propager après amélioration pour rendre le mode de la télésurveillance plus à l’aise, car non seulement le confinement mais aussi il y a pas mal des problèmes qui annulent ou empêchent l’examen, par exemple le trafic, la salle de classe occupée etc. Ce sont des problèmes rencontrés avant la crise sanitaire, qui peut être résolue en utilisant la télésurveillance à distance. L’efficacité est évidente, mais il faut aussi réfléchir d’éviter le fraude et protéger la vie privée.
références
https://www.businesscoot.com/fr/etude/le-marche-des-alarmes-et-de-la-videosurveillance-france
Technical Aspect
Aspect Technique de la Surveillance des examens
La tricherie des étudiants lors des examens est un phénomène répandu dans le monde entier, quel que soit le niveau de développement du pays. Avec l’expansion du cours distantiel, la surveillance des examens devient plus difficile à contrôler. Par conséquent, un suivi en temps réel est nécessaire pour garantir l’identité de l’étudiant en permanence pendant toute la période d’évaluation. C’est pourquoi plusieurs chercheurs proposent des approches, et la géneralité des approches se presente comme dans la figure suivante : 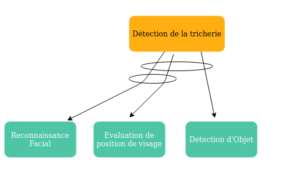 –Reconnaissance Facial :
–Reconnaissance Facial :
- Méthode de reconnaissance faciale en utilisant la librairie face_recognition et OpenCV[1] [2]dont le jeu de donné ne presente qu’une seule par personne et avec une bonne précision
- Methode d’utilisation OpenCV, Python, Apprentissage proffond [3]
–Evaluation orientation de visage :
- Méthode d’evaluation en utilisant Dlib et des divers calcules des coordonné dans le visage [4]
- Estimation de la possition faciale par apprentissage profond à partir de distributions d’étiquettes [5]: Utilise tensorflow
–Detection d’ object, il y a plusieurs modele pré-entrainer pour détecter les objets(écouteur, smartphone, ordinateur):
- SqueezeNet [6]
- ResNet50 [7]
- InceptionV3 [8]
- DenseNet121 [9]
- RetinaNet [10]
- YOLOv3 [11]
- TinyYOLOv3 [12]
Reference : [1] https://pypi.org/project/face-recognition/ [2] https://www.pyimagesearch.com/2018/09/24/opencv-face-recognition/ [3] https://www.pyimagesearch.com/2018/06/18/face-recognition-with-opencv-python-and-deep-learning/ [4] https://www.youtube.com/watch?v=ibuEFfpVWlU [5] https://openaccess.thecvf.com/content_ICCVW_2019/papers/HBU/Liu_Facial_Pose_Estimation_by_Deep_Learning_from_Label_Distributions_ICCVW_2019_paper.pdf [6] https://towardsdatascience.com/review-squeezenet-image-classification-e7414825581a [7] https://fr.mathworks.com/help/deeplearning/ref/resnet50.html;jsessionid=19893091227b5f13d159a4dbba6d [8] https://williamkoehrsen.medium.com/object-recognition-with-googles-convolutional-neural-networks-2fe65657ff90 [9] https://predictivehacks.com/object-detection-with-pre-trained-models-in-keras/ [10] https://keras.io/examples/vision/retinanet/ [11] https://thedatafrog.com/fr/articles/object-detection-darknet/ [12] https://imageai.readthedocs.io/en/latest/detection/
Project Description
Problem Definition
"La France affronte sa troisième vague épidémique du coronavirus, un an après avoir acté le premier confinement de la population sur tout le territoire national. Face aux variants (surtout le variant anglais) qui a entraîné une hausse des cas de Covid-19 (avec plus de 500 cas pour 100 000 habitants dans certaines zones) et mis les services de réanimation sous forte pression, 16 départements sont à nouveaux confinés à compter de vendredi minuit pour une durée de 4 semaines, a annoncé le Premier ministre Jean Castex, jeudi 18 mars."
C'est un grand problème actuel, et il devient plus en plus grave, c'est pour cela, il nous force de rester chez nous, concernant les études, la forme d'examen doit respecter le confinement, cependant il est souvent difficile de surveiller un examen pour évider la tricherie, surtout quand on est chez nous, on a plus de chances de tricher, mais ce qui est contre la règle de l'examen.
2. Les Problèmes rencontrés dans la vie
Il existe des cas dans la vie qu'on ne peut pas être présent à l'Université, surtout si c'est la journée de l'examen, c'est dommage pour les étudiants qui ont entièrement revu. Aussi pour les enseignants qui sont obligés de rester à la maison, il est compliqué de changer la date ou la salle pour l'examen.
Challenges & Motivation
Real and Complete Usecases
L’utilisation de ce système est facile, sauf il faut faire des installations des librairies, sinon pour ce qu’il a réalisé , ce n’est pas mal, on peut identifier les visages avec nos prénoms, être surveillé par rapport à l’orientation de la tête, si la personne regarde pas l’écran pendant quelques secondes, il y a des alarmes en rouge sur écran.
D’ailleurs, si la personne utilise le portable, l’autre ordinateur, ou faire référence à des livres, tous ces objets vont être stockés dans un répertoire. En plus si la personne parle, le terminal va afficher la détection enfin pour la durée du temps de l’exécution, cela peut être amélioré. 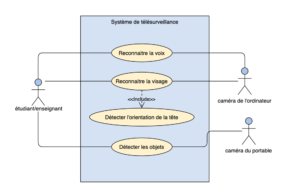
Technical Description
Le projet de la télésurveillance de l’examen à distance consiste notamment 5 parties: 1. La Reconnaissance Faciale
- Au début on veut suivre la vidéo https://www.youtube.com/watch?v=PmZ29Vta7Vc pour apprendre et essayer de faire la même chose en faisant un script pour prendre des photos en direct, et entraîner le modèle, mais cela nous donne des résultats avec très bas du taux de réussite. il a seulement 30% de taux de réussite.
- Donc on essaie de changer le modèle, et on trouve la libraire face_recognition est super, avec taux de réussite jusqu’à 99%, qui a besoin une seule image pour entraîner, et faire référence à ce site https://zhuanlan.zhihu.com/p/32961280 on a réussi à l’interpréter. Et utilise face_distance pour calculer la distance de non-similarité entre les images, et finalement faire la différence entre les inconnus et les personnes dans la base de données.
2. Evaluation de la position de visage
- Le principe de base qu’on a utilisé pendant l’évaluation d’orientation de la tête est inspirer dans ce https://www.youtube.com/watch?v=ibuEFfpVWlU ,le processus sont : detection de visage, récupération des points de contour de visage à l’aide d’utilisation de Dlib, calcul des divers distances principalement points de côté des yeux et le bout de nez,et reconnaissance de position de visage.
- On a rencontré des problèmes sur la reconnaissance d’inclinaison avant car si la personne se rapproche plus près de caméra, c’est un peu difficile de définir la position mais on utilise la méthode de division de grandeur pour essayer de résoudre cela.
3. Détection des objets
- Pour détecter d’objets, on utilise l’algorithme de réseau neuronal. Et il y a beaucoup de modèles. Comme SqueezeNet, ResNet50, InceptionV3, DenseNet121, RetinaNet, TinyYOLOv3
- On a essayé de nombreux modèles et en apprenant les tutoriels sur https://www.cnblogs.com/-wenli/p/11939377.html et https://www.cnblogs.com/hesse-summer/p/11335865.html on a choisi yolov3. Parce qu’il marche plus vite, il est plus précis et le résultat renvoyé de yolov3 est plus clair. Il peut détecter plus de 80 objets.
- On définit de notre coté les objets qui sont suspectible d’aider à tricher par exemple: L’ordinateur, le livre, le portable, la personne etc.
4. Détection de la voix
- On veut réaliser la détection de la voix en direct, mais après des recherches sur internet, il est vraiment compliqué donc, on décide de faire deux fonctions pour enregistrer la voix par 5 secondes, et lire le fichier et analyser en utilisant la librairie PyAudio et Wave
- Une vidéo pour l’enregistrement et la lecture de la vidéo https://www.youtube.com/watch?v=jbKJaHw0yo8, et une réference à comprendre l’analyse du fichier wave https://wizardforcel.gitbooks.io/hyry-studio-scipy/content/17.html
5. Multi-processus
- Pour une video, il faut afficher au moins 10 images par seconde. Donc, pour chaque image, il a moins de 1/10 seconde pour reconnaitre ou détecter. Mais dans le projet, il faut lire l’image, ensuite rechercher les visages sur cette image, ensuite reconnaitre les visages, trouver l’oriente des visages, détecter des objets et afficher l’image. S’il y a un seul processus, il marche 2 ou 3 secondes par chaque image. C’est-a-dire il affiche une image par 2 ou 3 seconde. Donc on utilise le multi-processus.
- Une réference sur multiprocessus en python https://docs.python.org/zh-cn/3.8/library/multiprocessing.html
Hardware
Materials
| Image | Name | Part Number | Price | Count | Link |
|---|---|---|---|---|---|
 | Ip webcam | / | gratuit | 1 | 🛒 |
Schematic
Software
Arduino Code
import dlib
import cv2
import os
#Bloquer les informations INFO + AVERTISSEMENT
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import face_recognition
import numpy as np
import pickle
import math
import time
from multiprocessing import Process,Queue
from imageai.Detection import ObjectDetection
import pyaudio
import wave
from array import array
from struct import pack
import datetime
known_face_encodings = []
known_face_names = []
dirname = "images/"
re_face_names = []
unknown_time = []
unknown_key = "unknown"
limit = 5
face_dis = 0.4
#Orientation
Ori_detector=dlib.get_frontal_face_detector()
Ori_predictor=dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def computer_detect(c_video_to_detect):
'''description
@author Zakia AMEZIANE (Détection des objets)
@author Andriatsiiavonana Sitraka Mbolatiana RAKOTOMAMONJY (Détection des objets)
@author Yiping BIAN (Améliorer le code)
Reconnaître s'il y a des personnes,des ordinateur, des livres ou des téléphones portables dans les objets capturés par la caméra de l'ordinateur
Args:
c_video_to_detect : Le processus pris par la caméra de l'ordinateur passe l'image au processus d'identification
'''
#Charger le modèle yolo v3
model_path = ('yolo.h5')
path = os.path.abspath(model_path)
detector = ObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath(path)
detector.loadModel()
custom_object = detector.CustomObjects(person=True, cell_phone=True, book=True, laptop=True)
while True:
while c_video_to_detect.empty():
time.sleep(0.1)
img_name = 'Objets_C/c_'+ time.strftime("%d-%m-%Y %H-%M-%S", time.localtime())+'.jpg'
p_time = time.strftime("%d-%m-%Y %H:%M:%S", time.localtime())
n_p = 0
n_b = 0
n_cp = 0
n_lap = 0
frame = c_video_to_detect.get()
frame = detector.detectObjectsFromImage(custom_objects=custom_object,input_image=frame, input_type='array',output_type='array')
#Comptez le nombre d'objets dans l'image
for eachObject in frame:
if (type(eachObject) != np.ndarray):
for eachO in eachObject:
if eachO['name'] == 'person':
n_p += 1
elif eachO['name'] == 'cell phone':
n_cp += 1
elif eachO['name'] == 'book':
n_b += 1
elif eachO['name'] == 'laptop':
n_lap += 1
#S'il y a plus d'une personne ou si vous avez un ordinateur portable, un livre ou un téléphone portable, enregistrez l'image
if (n_p > 1) or (n_b > 0) or (n_cp > 0) or (n_lap > 0):
print('-------------------')
print('Computer:')
print(p_time)
if n_p > 1:
print('Il y a',n_p,'personnes')
if n_b > 0:
print('Il y a',n_b,'livre')
if n_cp > 0:
print('Il y a',n_cp,'telephone')
if n_lap > 0:
print('Il y a',n_lap,'ordinateur')
print('We save the picture in',img_name)
cv2.imwrite(img_name,frame[0])
print('-------------------')
def recognize_faces(video_to_recog, recog_to_video,img,name):
'''description
@author Yiping BIAN
Args:
video_to_recog : Le processus pris par la caméra de l'ordinateur passe l'image au processus d'identification
recog_to_video : Le processus d'identification passe le nom au processus pris par la caméra de l'ordinateur
img : l'encording d'image de personne
name : le nom d'image de personne
'''
global re_face_names
global unknown_time
face_encode = img[0]
known_face_encodings.append(face_encode)
known_face_names.append(name)
while True:
while video_to_recog.empty():
time.sleep(0.1)
face_encodings = video_to_recog.get()
if len(face_encodings)>len(re_face_names):
for i in range(len(face_encodings)-len(re_face_names)):
re_face_names.append(unknown_key)
unknown_time.append(limit)
len_face = len(face_encodings)
len_name = len(re_face_names)
for i in range(len_name,len_face):
re_face_names.append(unknown_key)
unknown_time.append(limit)
for i in range(len_face,len_name):
del re_face_names[len_face]
del unknown_time[len_face]
n = 0
for face_encoding in face_encodings:
# calculer la distance de non-similarité entre les images
# par exemple, 0 répresente l'image reconnait correpondent exactement à l'image dans la base de données
# Afin d'éviter parfois de ne pas identifier une personne, s'il y a 5 "unknown" consécutives, nous changerons le résultat en "unknown"
i = 0
f_distance = face_recognition.face_distance(known_face_encodings, face_encoding)
for j in range(1,len(f_distance)):
if f_distance[i] > f_distance[j]:
i = j
if f_distance[i]<=face_dis:
re_face_names[n] = known_face_names[i]
unknown_time[n] = limit
elif unknown_time[n] == 1 :
re_face_names[n] = unknown_key
else:
unknown_time[n] -= 1
n = n+1
recog_to_video.put(re_face_names)
def Ori_detect(c_video_to_Ori,c_Ori_to_video):
'''description
@author Andriatsiiavonana Sitraka Mbolatiana RAKOTOMAMONJY
Identifier la direction de la tête ainsi la durée de la position
Args:
c_video_to_Ori : Le processus pris par la caméra de l'ordinateur passe l'image au processus d'identification
c_Ori_to_video : Le processus d'identification passe le résultat au processus pris par la caméra de l'ordinateur
'''
while True:
while c_video_to_Ori.empty():
time.sleep(0.1)
frame = c_video_to_Ori.get()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
Ori_faces = Ori_detector(gray)
if Ori_faces is not None:
i = np.zeros(shape=(frame.shape), dtype=np.uint8)
for face in Ori_faces:
landmarks = Ori_predictor(gray, face) #maquage des points de visage d'image(video webam) obtenue
#Détection des périphérique de l'oeil par rapport aux points visage marqué
d_eyes=math.sqrt(math.pow(landmarks.part(36).x-landmarks.part(45).x, 2)+math.pow(landmarks.part(36).y-landmarks.part(45).y, 2))
d1=math.sqrt(math.pow(landmarks.part(36).x-landmarks.part(30).x, 2)+math.pow(landmarks.part(36).y-landmarks.part(30).y, 2))
d2=math.sqrt(math.pow(landmarks.part(45).x-landmarks.part(30).x, 2)+math.pow(landmarks.part(45).y-landmarks.part(30).y, 2))
coeff=d1+d2
#Calcule des coefficients d'orientation de visage
# a1 pour connaitre l'orientation droit ou gauche
# a2 pour connaitre l'orientation haut ou bas
# a3 pour connaitre l'inclinaison
a1=int(250*(landmarks.part(36).y-landmarks.part(45).y)/coeff)
a2=int(250*(d1-d2)/coeff)
cosb=min((math.pow(d2, 2)-math.pow(d1, 2)+math.pow(d_eyes, 2))/(2*d2*d_eyes), 1)
a3=int(250*(d2*math.sin(math.acos(cosb))-coeff/4)/coeff)
#détermination de des abscisse et ordonné des point de marquage de visage
txt = " regarde "
for n in range(0, 68):
x=landmarks.part(n).x
y=landmarks.part(n).y
if n==30 or n==36 or n==45:
cv2.circle(i, (x, y), 3, (255, 255, 0), -1)
else:
cv2.circle(i, (x, y), 3, (255, 0, 0), -1)
# définir les différentes positions par rapport à les résultats obtenu au-dessus
flag=1
if a2<-40:
txt+="a droite "
flag=0
if a2>40:
txt+="a gauche "
flag=0
if a3<-10:
txt+="en haut "
flag=0
if a3>10:
txt+="en bas "
flag=0
if flag:
txt+="la camera "
if a1<-40:
txt+="et incline la tete a gauche "
if a1>40:
txt+="et incline la tete a droite "
c_Ori_to_video.put(txt)
def real_time_face_detect(video_to_recog, recog_to_video, c_video_to_detect, c_video_to_Ori, c_Ori_to_video):
'''description
@author Xiaotong QIAN (proposer le code original)
@author Yiping BIAN (améliorer le code)
Détection en temps réel du nom du visage
et la durée de la position
Args:
video_to_recog : Le processus pris par la caméra de l'ordinateur passe l'image au processus de reconnaissance de visage
recog_to_video : Le processus de reconnaissance de visage passe le nom au processus pris par la caméra de l'ordinateur
c_video_to_detect : Le processus pris par la caméra de l'ordinateur passe l'image au processus d'identification de l'article
c_video_to_Ori : Le processus pris par la caméra de l'ordinateur passe l'image au processus de reconnaissance orientée visage
c_Ori_to_video : Le processus de reconnaissance orientée visage passe le résultat au processus pris par la caméra de l'ordinateur
'''
# Obtenez une référence à la webcam n ° 0 (celle par défaut)
video_capture = cv2.VideoCapture(0)
process_this_frame = True
scale_factor = 4
name = "" # initialiser le nom de la personne
debut_seconds = time.time() # le début du lancement de la caméra
dernier_seconds = debut_seconds # initialiser le dernier_seconds pour l'utiliser dans le suivant
gl_txt = "" # initialiser gl_txt comme un variable pour aider à calculer la durée de la position
txt = ""
face_names = []
print("press [q] to quit!")
while True:
# Prenez une seule image de vidéo
ret, frame = video_capture.read()
# Redimensionner l'image de la vidéo à 1/4
# pour un traitement de reconnaissance faciale plus rapide
# processus
if c_video_to_detect.empty():
c_video_to_detect.put(frame)
small_frame = cv2.resize(
frame, (0, 0), fx=1.0 / scale_factor, fy=1.0 / scale_factor)
# Convertir l'image de la couleur BGR (utilisée par OpenCV)
# en couleur RVB (utilisée par face_recognition)
rgb_small_frame = small_frame # [:, :, ::-1] # mac unnecessary
# Traiter uniquement toutes les autres images de la vidéo pour gagner du temps
if process_this_frame:
# Trouvez tous les visages
# et encodages de visage dans l'image actuelle de la vidéo
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(
rgb_small_frame, face_locations)
if video_to_recog.empty() and (len(face_encodings)>0):
video_to_recog.put(face_encodings)
if not recog_to_video.empty():
face_names = recog_to_video.get()
len_face = len(face_encodings)
len_name = len(face_names)
for i in range(len_name,len_face):
face_names.append(unknown_key)
for i in range(len_face,len_name):
del face_names[len_face]
process_this_frame = not process_this_frame
# Afficher les résultats
for pos, name in zip(face_locations, face_names):
(top, right, bottom, left) = pos
# Mettre à l'échelle les emplacements des visages,
# car l'image dans laquelle nous avons détecté était
# mis à l'échelle à 1/4 de la taille
top *= scale_factor
right *= scale_factor
bottom *= scale_factor
left *= scale_factor
# Dessiner une boîte autour du visage
cv2.rectangle(frame, (left, top), (right, bottom), (255, 0, 0), 2)
# Afficher une étiquette avec un nom sous la visage
if name == unknown_key :
cv2.putText(frame, name, (left, top+30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
else:
cv2.putText(frame, name, (left, top+30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
# Début de la durée de la position
if c_video_to_Ori.empty():
c_video_to_Ori.put(frame)
if not c_Ori_to_video.empty():
txt = c_Ori_to_video.get()
txt = name + txt
# calcule d'intervalle de seconde de chaque position
if txt != gl_txt:
intervalle_de_seconde = dernier_seconds - debut_seconds
mess = txt + "pendant {:2f} seconde".format(intervalle_de_seconde)
if intervalle_de_seconde > 0.1:
print(time.strftime("%d-%m-%Y %H:%M:%S", time.localtime()),mess)
gl_txt = txt
debut_seconds = time.time()
dernier_seconds = time.time()
intervalle_de_seconde = dernier_seconds - debut_seconds
# On suppose 5 secondes est suspectible
if (intervalle_de_seconde > 5) & (txt != name + " regarde " + "la camera ") :
mess = txt + "deja superieur a 3 seconde "
cv2.putText(frame, mess, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
else :
mess = txt + "pendant {:2f} seconde".format(intervalle_de_seconde)
cv2.putText(frame, mess, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 1)
# Fin de la durée de la position
# Afficher les résultats
cv2.imshow('Video', frame)
# appuyez 'q' pour quitter!
if cv2.waitKey(1) & 0xFF == ord('q'):
intervalle_de_seconde = dernier_seconds - debut_seconds
mess = txt + "pendant {:2f} seconde".format(intervalle_de_seconde)
print(time.strftime("%d-%m-%Y %H:%M:%S", time.localtime()),mess)
break
# Relâchez la poignée de la webcam
video_capture.release()
cv2.destroyAllWindows()
def telephone_detect(t_video_to_detect):
'''description
@author Zakia AMEZIANE (Détection des objets)
@author Andriatsiiavonana Sitraka Mbolatiana RAKOTOMAMONJY (Détection des objets)
@author Yiping BIAN (Améliorer le code)
Args:
t_video_to_detect : Le processus pris par la caméra du téléphone passe l'image au processus d'identification de l'article
'''
model_path = ('yolo.h5')
path = os.path.abspath(model_path)
detector = ObjectDetection()
detector.setModelTypeAsYOLOv3()
detector.setModelPath(path)
detector.loadModel()
custom_object = detector.CustomObjects(person=True, cell_phone=True, book=True, laptop=True)
while True:
while t_video_to_detect.empty():
time.sleep(0.1)
img_name = 'Objets_T/t_'+ time.strftime("%d-%m-%Y %H-%M-%S", time.localtime())+'.jpg'
p_time = time.strftime("%d-%m-%Y %H:%M:%S", time.localtime())
n_p = 0
n_b = 0
n_cp = 0
n_lap = 0
frame = t_video_to_detect.get()
frame = detector.detectObjectsFromImage(custom_objects=custom_object,input_image=frame, input_type='array',output_type='array')
#Comptez le nombre d'objets dans l'image
for eachObject in frame:
if (type(eachObject) != np.ndarray):
for eachO in eachObject:
if eachO['name'] == 'person':
n_p += 1
elif eachO['name'] == 'cell phone':
n_cp += 1
elif eachO['name'] == 'book':
n_b += 1
elif eachO['name'] == 'laptop':
n_lap += 1
#S'il y a plus d'un ordinateur portable ou si vous avez une personne, un livre ou un téléphone portable, enregistrez l'image
if (n_p > 0) or (n_b > 0) or (n_cp > 0) or (n_lap > 1):
print('-------------------')
print(p_time)
print("Telephone:")
if n_p > 0:
print('Il y a',n_p,'personnes')
if n_b > 0:
print('Il y a',n_b,'livre')
if n_cp > 0:
print('Il y a',n_cp,'telephone')
if n_lap > 1:
print('Il y a',n_lap,'ordinateur')
print('We save the picture in',img_name)
cv2.imwrite(img_name,frame[0])
print('-------------------')
def telephone_video(addr,t_video_to_detect):
'''description
@author Yiping
Args:
addr : L'adresse de l'application ipwebcam
t_video_to_detect : Le processus pris par la caméra du téléphone passe l'image au processus d'identification de l'article
'''
# Obtenez une référence à la webcam n ° 0 (celle par défaut)
url = "http://"+addr+"/video" # url du l'image
video_capture = cv2.VideoCapture(0)
video_capture.open(url)
process_this_frame = True
scale_factor = 4
debut_seconds = time.time() # le début du lancement de la caméra
dernier_seconds = debut_seconds # initialiser le dernier_seconds pour l'utiliser dans le suivant
gl_txt = "" # initialiser gl_txt comme un variable pour aider à calculer la durée de la position
picture_size = 0.5
print("Telephone is opening!")
while True:
# Prenez une seule image de vidéo
ret, frame = video_capture.read()
if t_video_to_detect.empty():
t_video_to_detect.put(frame)
x,y = frame.shape[0:2]
frame = cv2.resize(frame, (int(y*picture_size),int(x*picture_size)))
# Afficher les résultats
mess = "Press [q] to quit. Press [-] to shrink. Press [+] to enlarge."
cv2.putText(frame, mess, (int(10*picture_size*2), int(30*picture_size*2)), cv2.FONT_HERSHEY_SIMPLEX, 0.8*picture_size*2, (0, 255, 0), int(2*picture_size*2))
cv2.imshow('Video', frame)
# appuyez 'q' pour quitter!
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
if key == ord('+'):
if picture_size < 1:
picture_size += 0.05
if key == ord('-'):
if picture_size > 0.1:
picture_size -= 0.05
# Relâchez la poignée de la webcam
video_capture.release()
cv2.destroyAllWindows()
def init():
'''description
@author Andriatsiiavonana Sitraka Mbolatiana RAKOTOMAMONJY
Prendre une photo d'utilisateur pour entraîner le modèle
'''
cam=cv2.VideoCapture(0)
id=input("Entrez votre prénom : ")
while(True):
ret,frame=cam.read()
face_locations = face_recognition.face_locations(frame) # Obtenir la position des valeurs propres
face_encodings = face_recognition.face_encodings(frame, face_locations) # le codage des valeurs propres du visage
for pos in face_locations:
(top, right, bottom, left) = pos
cv2.rectangle(frame, (left, top), (right, bottom), (255, 0, 0), 2)
mess = "Press [s] to take a photo."
mess1 = "Press [y] to confirm. Press [n] to re-shoot."
frame1 = frame * 1
cv2.putText(frame, mess, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Face",frame)
key = cv2.waitKey(1) & 0xFF
if (key == ord('s')) or (key == ord('S')):
if len(face_locations)!=1:
print("It must be 1 and only 1 person!")
continue
cv2.putText(frame1, mess1, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Face",frame1)
while True:
k = cv2.waitKey(1) & 0xFF
if (k == ord('y')) or (k == ord('Y')) or (k == ord('n')) or (k == ord('N')):
break
if (k == ord('y')) or (k == ord('Y')):
time.sleep(0.1)
break
cam.release()
cv2.destroyAllWindows()
return face_encodings,id
def record(record_to_read,record_temp_data):
'''description
@author Xiaotong QIAN
Enregistrer la voix autour de l'ordinateur
Args:
record_to_read : Le processus d'enregistrement transmet le nom du fichier au processus de reconnaissance
record_temp_data : Le processus d'enregistrement transmet le temps au processus de reconnaissance
'''
s=0
while True:
time.sleep(1)
filename = str(s) + '.wav'
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 44100
RECORD_SECONDS = 5
p = pyaudio.PyAudio()
# objet de flux ouvert en entrée
stream = p.open(
format = FORMAT,
channels = CHANNELS,
rate = RATE,
input = True,
frames_per_buffer = CHUNK
)
# enregistrer le temps local
temp_date = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')[:-4]
frames = []
for i in range(0,int(RATE / CHUNK * RECORD_SECONDS)) :
if stream.read(CHUNK):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
# enregistrement terminé
# stocker la voix dans le fichier filename
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
s+=1
record_to_read.put(filename)
record_temp_data.put(temp_date)
def read(record_to_read,record_temp_data):
'''description
@author Xiaotong QIAN
Lire et analyser la voix stocké dans les fichiers
Args:
record_to_read : Le processus d'enregistrement transmet le nom du fichier au processus de reconnaissance
record_temp_data : Le processus d'enregistrement transmet le temps au processus de reconnaissance
'''
while True:
while record_to_read.empty():
time.sleep(0.1)
inputFile = record_to_read.get()
while record_temp_data.empty():
time.sleep(0.1)
temp_date = record_temp_data.get()
debut = datetime.datetime.now()
# Ouvrir le document WAV
f = wave.open(inputFile, "rb")
# Lire les informations de format
# (nchannels, sampwidth, framerate, nframes, comptype, compname)
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
# Lire les données de forme d'onde
str_data = f.readframes(nframes)
f.close()
os.remove(inputFile)
# Convertir les données de forme d'onde en tableau
wave_data = np.frombuffer(str_data, dtype=np.short)
wave_data.shape = -1, 2
wave_data = wave_data.T
time1 = np.arange(0, nframes) * (1.0 / framerate)
# sélectionner la voix qui dépasse 50 (selon notre test) et le temps correspondant
wave_data_index = [index for index, i in enumerate(wave_data[0]) if abs(i) > 50]
time_f = [round(i,2) for i in time1[wave_data_index]]
time_final = sorted(set(time_f),key=time_f.index)
# Afficher la partie que la personne parle pendant plus de 0.5sec
if len(time_final) > 1:
last = time_final[0]
for i in range(1,len(time_final)):
if round(time_final[i],2) != round(time_final[i-1]+0.01,2):
if round((time_final[i-1] - last),2) > 0.5:
head = (datetime.datetime.strptime(temp_date, '%Y-%m-%d %H:%M:%S.%f') + datetime.timedelta(seconds = + round(last,2))).strftime('%Y-%m-%d %H:%M:%S.%f')[:-4]
tail = (datetime.datetime.strptime(temp_date, '%Y-%m-%d %H:%M:%S.%f') + datetime.timedelta(seconds = + round(time_final[i-1],2))).strftime('%Y-%m-%d %H:%M:%S.%f')[:-4]
print(head,'à',tail," la personne parle")
last = time_final[i]
if round(time_final[-1],2) != round(time_final[i-1]+0.01,2):
head = (datetime.datetime.strptime(temp_date, '%Y-%m-%d %H:%M:%S.%f') + datetime.timedelta(seconds = + round(last,2))).strftime('%Y-%m-%d %H:%M:%S.%f')[:-4]
tail = (datetime.datetime.strptime(temp_date, '%Y-%m-%d %H:%M:%S.%f') + datetime.timedelta(seconds = + round(time_final[-1],2))).strftime('%Y-%m-%d %H:%M:%S.%f')[:-4]
print(head,'à',tail," la personne parle")
fin = datetime.datetime.now()
if __name__ == '__main__':
'''
Étant donné que la reconnaissance des éléments, la reconnaissance faciale et
la reconnaissance de l'orientation des visages sont indépendantes les unes des autres
et nécessitent beaucoup de temps pour les calculs, nous utilisons plusieurs processus.
Sinon, la vidéo affiche une imagee par quelques secondes.
Le traitement du téléphone mobile et la reconnaissance vocale sont également la même raison.
'''
img,name = init()
video_to_recog = Queue()
recog_to_video = Queue()
c_video_to_detect = Queue()
t_video_to_detect = Queue()
c_video_to_Ori = Queue()
c_Ori_to_video = Queue()
record_to_read = Queue()
record_temp_data = Queue()
'''
expliquations des variables qui s'agit du processus
comp_recog_face : Le processus de reconnaissance faciale sur l'écran de la caméra d'ordinateur
comp_video : Le processus de lecture de l'écran de la caméra d'ordinateur
comp_detect : Le processus de reconnaissance d'objet d'écran de caméra d'ordinateur
comp_ori : Le processus de reconnaissance orientée visage sur l'écran de la caméra d'ordinateur
comp_record : Le processus d'enregistrement informatique
comp_read : Le processus de reconnaissance des enregistrements informatiques
tele_video : Le processus de lecture de l'écran de la caméra du téléphone portable
tele_detect : Le processus de reconnaissance d'objet d'écran de caméra de téléphone portable
'''
comp_recog_face = Process(target = recognize_faces,args = (video_to_recog, recog_to_video,img,name))
comp_video = Process(target = real_time_face_detect,args = (video_to_recog, recog_to_video,c_video_to_detect,c_video_to_Ori,c_Ori_to_video))
comp_detect = Process(target = computer_detect,args = (c_video_to_detect,))
comp_ori = Process(target = Ori_detect, args = (c_video_to_Ori,c_Ori_to_video))
comp_record = Process(target = record, args = (record_to_read, record_temp_data))
comp_read = Process(target = read, args = (record_to_read, record_temp_data))
comp_recog_face.daemon = True
comp_detect.daemon = True
comp_ori.daemon = True
comp_record.daemon = True
comp_read.daemon = True
addr = input("Entrez l'adresse de video : http://")
comp_recog_face.start()
comp_detect.start()
comp_video.start()
comp_ori.start()
comp_record.start()
comp_read.start()
tele_video = Process(target = telephone_video,args = (addr,t_video_to_detect,))
tele_detect = Process(target = telephone_detect,args = (t_video_to_detect,))
tele_video.daemon = True
tele_detect.daemon = True
tele_video.start()
tele_detect.start()
comp_video.join()
External Services
Application pour connecter la caméra du portable sur ordinateur