
Compteur d'objets
Il s'agit d'un dispositif capable de détecter et compter les objets selon leurs forme , par le biais d'une application mobile sous Android
Slides & Videos
Members
| Name | Contribution |
|---|---|
| Zaynab Romene | 1-Detection et comptage sur des images fixes et une vidéo enregistré sur l'ordinateur. 2-Developpement d'une partie de l'application Mobile sur Android Studio . |
| El mehdi Baaziz | 1-Préparaion de la base de donnée 2-Entrainement sous TensorFlowLite. |
| sakis Nour el houda | 1-Detection et comptage en temps réel. 2-Developpement d'une partie de l'application Mobile sur Android Studio . |
State of the Art
Business Aspect
1-Introduction
La détection et le suivi d’objets sont parmi les problèmes les plus étudiés ces dernières années. Ce sont des tâches importantes et difficiles dans de nombreuses applications de vision par ordinateur telles que la robotique, la vidéosurveillance [21]-[23]. La détection d’objet consiste à localiser l’objet dans chacune des trames d’une séquence vidéo. Le suivi d’objet est le processus de localisation spatio-temporelle d’un objet en mouvement au cours d’une séquence vidéo. Chaque méthode de suivi d’objet nécessite un mécanisme de détection d’objet, soit dans chaque trame ou lorsque l’objet apparaît d’abord dans la vidéo
1-Placement de l’IOT dans l’industrie d’aujourd’hui :
L’Internet industriel des objets abrégé en IoT, apporte aujourd’hui d’importantes modifications dans la manière de produire, de gérer et de communiquer dans l’entreprise.
Le potentiel économique que l’IIoT présente est considérable : une contribution à hauteur de 14 200 milliards de dollars à la production mondiale d’ici 2030 selon les estimations d’Accenture en 2015, ainsi qu’une part du marché mondial de l’IoT (industriel et grand public) atteignant les 195 milliards de dollars en 2022 d’après les prévisions du cabinet d’analyse Markets & Markets cité par Les Echos 2.
Le déploiement d’objets connectés n’a de sens que si l’entreprise se place dans une logique de continuité dans la transformation numérique de ses processus.
les moyens de production deviennent à la fois connectés et intelligents. De tels systèmes génèrent des quantités considérables de données (Big Data) dont la qualité d’analyse et d’exploitation détermine en grande partie la capacité d’une organisation à améliorer son fonctionnement, à rester concurrentielle et performante.
2-La reconnaissance des Objets :
l’IA est un très vaste domaine et les applications sont diverses et variées. Il est possible de distinguer plusieurs branches notamment La reconnaissance des Objets qui fera le sujet de notre projet.
La détection et le suivi d’objets sont parmi les problèmes les plus étudiés ces dernières années. Ce sont des tâches importantes et difficiles dans de nombreuses applications de vision par ordinateur telles que la robotique, la vidéosurveillance .
La détection d’objet consiste à localiser l’objet dans chacune des trames d’une séquence vidéo. Le suivi d’objet est le processus de localisation spatio-temporelle d’un objet en mouvement au cours d’une séquence vidéo. Chaque méthode de suivi d’objet nécessite un mécanisme de détection d’objet, soit dans chaque trame ou lorsque l’objet apparaît d’abord dans la vidéo.
Cette technique permet de gagner en précision et en vitesse d’exécution en interagissant avec leur environnement. Autonomes et capables d’assurer différentes tâches, ils savent prendre des « décisions » en fonction de ce que leur indiquent, d’une part les capteurs, et d’autre part le système d’information auxquels ils sont reliés.
Avec un système ou une plateforme de reconnaissance d’image, il est possible d’automatiser des processus métiers et ainsi d’améliorer la productivité. Effectivement, une fois qu’un modèle reconnaît un élément sur une image, il peut être programmé pour réaliser une action particulière. Plusieurs cas d’usages différents sont déjà en production et sont déployés à grande échelle, dans divers industries et secteurs.
Les API de reconnaissance d’objets , permettent aux professionnels d’entraîner des modèles de réseaux de neurones préexistants à la détection d’objets ou de façonner leurs propres modèles, se veut simplifiée et plus performante. De cette façon, elle est désormais capable de fonctionner sur des appareils moins sophistiqués comme des smartphones, et ce grâce à la technologie Mobile Nets, passée également en open source récemment.
D’après JDN statistica , le futur de l’intelligence artificielle généralement ainsi que celui de la reconnaissance des objets pour ces diverses applications : Localisation , analyse .. restera en croissance exponentielle avec des chiffres d’affaires significatives d’ici 2025 :
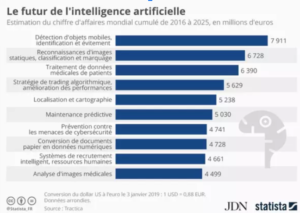
3-Domaines D’application de la détection d’objets :
On parlant de qui traite de la reconnaissance d’objets dans le monde , on trouve que Google n’est pas le seul à vouloir démocratiser l’apprentissage automatique des IA sur smartphones. Depuis plusieurs mois, d’autres géants de la tech ont également investi le terrain : Facebook avec ses Framework Caffe2 et PyTorch, Microsoft avec Cognitive Toolkit ou encore Amazon avec Apache MXNet.
Il s’agit d’une application qui touche divers secteurs, par exemple, dans le secteur de la télécommunication, il a été possible de déployer une solution d’automatisation du contrôle qualité. En effet, les techniciens opérant chez des particuliers utilisent un système de reconnaissance d’image afin de contrôler la qualité de leurs installations.
Les applications de l’internet industriel des objets couvrent aussi le domaine de la sécurité. Elles donnent la possibilité de disposer d’un surcroît de protection dans l’environnement de travail, aussi bien pour les opérateurs que pour les équipements.
également , un système de vidéo surveillance intelligent, basé sur la reconnaissance d’image, est capable de signaler tous comportements ou situations inhabituels au sein des parkings.
Dans un autre registre, dans l’industrie certains dispositifs poussés sont capable de réagir en conséquence d’une anomalie , par exemple, programmées pour stopper immédiatement toute action lorsque via les algorithmes implémentés sont capable de détecter la présence d’un objet ou d’une personne dans un périmètre prédéfini, et ce, pour ne pas mettre ces derniers en danger pour assurer le bon fonctionnement du processus industriel .
La reconnaissance d’image peut donc être déployée aussi bien dans la télécommunication que dans la télésurveillance mais également dans le BTP ou encore l’industrie pharmaceutique .
Également , dans le cadre de la reconnaissance des objets , le projet ImageNet a organisé un concours annuel : ImageNet Large Scale Visual Recognition Challenge ou “Compétition ImageNet de Reconnaissance Visuelle à Grande Échelle”. Elle consistait en une compétition logicielle dont le but était de détecter et classifier précisément
des objets et des scènes dans les images naturelles.
Ces exemples présentent des technologies qui sont l’avenir d’une économie compétitive et innovante où l’industrie tend vers le concept d’Usine du Futur, une usine au sein de laquelle les facultés d’innovation et de création sont décuplées et où les technologies sont au service des collaborateurs pour rendre efficientes leur productivité et leurs conditions de travail.
4-Qui traite la détection d’objets en France et dans le monde :
Dans le Monde :
- Le Robot Max-AI , fabriqué par une société américaine, est capable de reconnaître certains types de déchets indésirables sur le tapis roulant d’une chaîne de tri et, avec un bras articulé, de les en écarter. Installé depuis juin sur un site du groupe veolia à Amiens, Le robot peut effectuer 3 600 gestes de tri par heure, contre environ 2 200 pour un opérateur humain. Dans un rapport de 2014, l’ADEME estimait que l’automatisation des centres de tri allait engendrer la suppression de 3 500 à 5 000 emplois.
- Bay Labs une des start-up qui utilise l’apprentissage profond dans l’imagerie, en utilisant L’IA Pour Le Diagnostic Des Maladies Cardiaques Bay Labs a également développé une suite logicielle d’analyse d’échocardiographie, appelés EchoMD
- ViSenze, une jeune pousse singapourienne qui a développé une série de solutions de reconnaissance d’images pour l’e-commerce basées sur le machine Learning. Sa solution permet aux consommateurs de chercher des produits sur les sites e-commerce de ces entreprises en y postant une photo de vêtement prise depuis leur téléphone par exemple, pour trouver des articles qui y ressemblent .
En France :
- les deux start-up Deepomatic et Sicara. : dans la reconnaissance des plateaux au moment du passage en caisse dans leurs , il s’agit d’une borne équipée de trois appareils photo qui revendique un taux de confiance de l’ordre de 95 %
- L’entreprise AUXILIA propose une Intelligence Artificielle basé sur la reconnaissance d’images pour l’amélioration de la sûreté dans les zones contrôlées. Notre logiciel détecte automatiquement les armes ou autres objets dangereux sur les scanners rayons X des bagages et des marchandises. Aéroports, musées, concerts, prisons, centrales nucléaires, fret et colis: dans tout secteur contrôlé, Grâce à des modèles de Deep Learning, la détection est automatique sur des images qui proviennent directement des machines rayon X, que l’on trouve par exemple à l’aéroport. L’IA localise et caractérise les objets prohibés en les mettant en valeur à l’écran.
- Flyinstinct est une start-up dans le domaine de l’aéroportuaire qui travaille sur un projet qui permet d’améliorer la détection d’objets tels que des pièces d’avion (boulon, lamelle), outils du personnels ou encore articles tombés du bagage d’un passager sur les pistes d’avion. Ces objets, appelés FOD (Foreign Object Debris), peuvent causer de graves dommages aux avions allant jusqu’à provoquer des crashs c’est un système de caméra doté d’une intelligence artificielle de pointe qui permet d’indiquer à l’inspecteur la présence de FOD sur la piste. Celui-ci peut alors le retirer de la piste et ainsi renforcer la sécurité des avions et des voyageurs.
- La start-up EasyPicky a été créée en 2017 avec l’idée de développer une intelligence artificielle basée sur la reconnaissance vidéo en instantané, qui puisse fonctionner sans connexion Internet, et qui puisse également, être déployée sur n’importe quel système embarqué dans le but d’accélérer, faciliter et renforcer le contrôle des planogrammes, c’est une application qui avec des relevés faits en moins de 2 minutes, permet la reconnaissance en 50ms des produits et le calcul des KPIs associés obtenus en instantané même s’il n y a pas de réseau en magasin.
Technical Aspect
Plusieurs technologies et analyses sont utilisées pour reconnaître des images ou même de trouver des objets à l’intérieur d’une image. Dans cette partie, on décortiquera les analyses les plus performantes et utilisés. Ce rapport, dont le sujet Analyse d’images et reconnaissance d’objets pour les besoins de la Police cantonale, nous a beaucoup aidé pour comprendre les principes : https://doc.rero.ch/record/329755/files/TB_Hamouti_Aur_lien_Analyse_images_et_reconnaissance_objets.pdf
Parmi ces analyses utilisées dans la détection des objets on distingue :
- Analyses statistiques : Analyse discriminante
Selon un extrait de la revue de statistique appliquée, l’analyse discriminante est une technique de classement ou de reconnaissance des formes par opposition à la typologie ou à la classification. C’est une technique statistique prédictive ou/et descriptive qui vise à décrire, expliquer et prédire l’appartenance à des groupes prédéfinis d’un ensemble d’observations à partir d’une série de variables prédictives. Il suffit pour cela d’extraire les caractéristiques des images puis d’y appliquer l’analyse discriminante.
https://fr.wikipedia.org/wiki/Analyse_discriminante
L’évaluation de cette technique s’effectue sur deux niveaux :
- Évaluer le pouvoir discriminant d’un axe factoriel
- Évaluer le pouvoir discriminant d’un ensemble d’axes factoriels.
L’idée sous-jacente est de pouvoir déterminer le nombre d’axes suffisants pour distinguer les groupes d’observations dans le nouveau système de représentation.
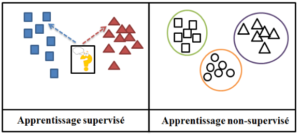
2. Apprentissage automatique : L’apprentissage automatique aussi appelé par son équivalent anglophone Machine Learning est utilisé en intelligence artificielle et en science et analyse des données (Analytics and Data Science). Il permet de détecter des objets dans des images et de les classe en utilisant grande quantité des photos.
2.1. Apprentissage supervisé : Il met en œuvre des données d’entrée et de sortie (inputs/outputs) sont appelés « supervisés ». Il consiste à apprendre une fonction de prédiction à partir d’exemples annotés appelé base d’apprentissage.
Cette méthode permet de résoudre les problèmes de prédiction d’une variable quantitative (comme les problèmes de régression) et les problèmes de prédiction d’une variable qualitative (des problèmes de classification par exemple).
https://fr.wikipedia.org/wiki/Apprentissage_supervis%C3%A9
2.2. Apprentissage non supervisé : C’est un apprentissage automatique ou données ne sont pas étiquetées. Autrement dit, en entrainant un modèle on ne connait que les entrées. Il s’agit donc de découvrir les structures sous-jacentes à ces données non étiquetées.
https://fr.wikipedia.org/wiki/Apprentissage_non_supervis%C3%A9
3. Réseau de neurones artificiels RNA : C’est une technique illustrée de réseau de neurones biologiques et qui par la suite s’est rapproché des méthodes statistiques. Il s’agit un assemblage interconnecté d’éléments, d’unités ou de nœuds de traitement simples. Les réseaux de neurones apprennent par induction, c’est-à-dire par expérience, en étant confrontés à des données en entrée (input) et en sortie (output).
Ils sont capables de capturer des informations contenues dans de grandes quantités de données et de créer des modèles complexes. Néanmoins, ceux de grande taille, prennent souvent beaucoup de temps à se former et se construire
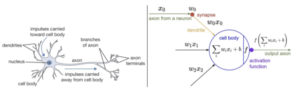
La simulation d’un neurone formel, la fonction mathématique est plutôt simple à comprendre.
On fait la somme des signaux en entrées (x) multipliés par le poids des synapses (w), ce qui donne :
Somme = ( x1 * w1 ) + ( x2 * w2 ) + ( x3 * w3 ) + …
Si cette somme est supérieure à un certain seuil alors le signal en sortie est de 1sinon il est de 0.
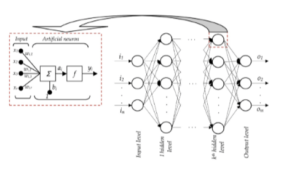
4. Apprentissage profonde DNN : Le deep learning ou apprentissage profond est une pratique d’IA issue de l’apprentissage automatique ou machine learning.
Il représente l’idée de couches successives de représentations. Le nombre de couches qui contribuent à un modèle de données définit la profondeur du modèle. Les réseaux de neurones profonds sont d’ailleurs parfois appelés « réseaux multicouches ».
Il déploie un réseau de neurones artificiel préalablement entraîné.
Après avoir été préalablement entraîné sur une base d’exemples « Dataset », un réseau de neurones artificiel pourra typiquement être utilisé dans la reconnaissance d’images.
Les réseaux de neurones mettant en pratique le principe de l’apprentissage profond sont appelés réseaux de neurones profonds (DNN).
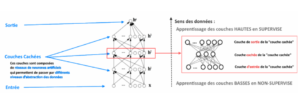
5. Réseau de neurones à convolution (CNN) : Les réseaux de neurones à convolution soient particulièrement bien adaptés à la reconnaissance d’image parce que La convolution est un outil mathématique simple qui est très largement utilisé pour le traitement d’image.
La convolution agit comme un filtrage. On définit une taille de fenêtre qui va se balader à travers toute l’image. Une fenêtre sera positionnée tout en haut à gauche de l’image puis elle va se décaler d’un certain nombre de cases vers la droite et lorsqu’elle arrivera au bout de l’image, elle se décalera d’un pas vers le bas ainsi de-suite jusqu’à ce que le filtre soit parcourue la totalité de l’image.
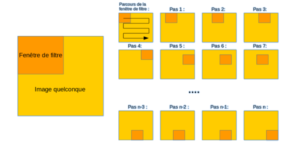
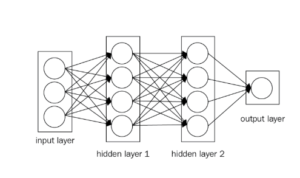
Il existe trois couches principales dans un simple réseau de neurones à convolution (CNN). Ce sont la couche de convolution, la couche de mise en commun et la couche entièrement connectée.
Project Description
Problem Definition
Challenges & Motivation
Aujourd'hui, tous les domaines utilisent des caméras et des images dans leurs activités notamment imagerie médicale, industrie, transport, surveillance, agriculture , robotique etc.
L'objectif de ce projet c’est de faire la reconnaissance et le comptage d’objets à partir d’une CaméraPI par le biais d’un algorithme python.
Après avoir réussi à détecter et compter des objets sur la base “coco names” en se basant sur une API pré-entraîné , ce type de modèles sont généralement utilisés pour gérer des cas d'utilisation usuels de la vision : objets, personnes, animaux, contextes, véhicules, visages, etc
En cherchant plus de précision , on a essayé d’intégrer la notion de deep Learning en faisant un modèle spécifique à une application précise d'où l'entraînement d’une base de données particulière sous TenserFlow .
Le but c’est de créer des modèles spécifiques réalisés uniquement pour un projet unique et par la suite d’élaborer une comparaison en termes de performance entre les deux bases ceci s'établit en s' appuyant sur la fiabilité , la rapidité et du résultat .
Pour le résultat, on a réalisé une application mobile sous android avec le logiciel Android Studio qui reçoit le fichier de la base de données entraînée sous TensorFlow et permet de faire la détection sur des photos prises depuis le téléphone.
Cette réalisation nous servira pour la suite d’un autre projet qui est un Bras Robotisé Pinscher X100 programmé sous ROS , capable de détecter une forme de pièces , les compter et par la suite les trier dans l’emplacement adéquat.
Real and Complete Usecases
Technical Description


Hardware
Materials
| Image | Name | Part Number | Price | Count | Link |
|---|---|---|---|---|---|
| il s'agit d'un projet 100% software | - | - | - | 🛒 |
Schematic
Software
Arduino Code
Ceci est un lien Drive qui contient tous les fichiers du projet https://drive.google.com/drive/folders/1WKikxKwcX8YCqNMtTikgBaLBlj2scsL_?usp=sharing
External Services
0